
Ergebnisse

Veröffentlichungen
Im Umfeld des Projekts sind folgende wissenschaftliche Arbeiten entstanden:
Wachsmuth & Bujna 2011: Henning Wachsmuth and Kathrin Bujna. Back to the Roots of Genres: Text Classification by Language Function. In: Proceedings of the 5th International Joint Conference on Natural Language Processsing (IJCNLP'11), AFNLP, Chiang Mai, Thailand, pages 632-640, November 2011.
Download [paper] (900 KB)
Wachsmuth et. al. 2011: Henning Wachsmuth, Benno Stein, and Gregor Engels. Constructing Efficient Information Extraction Pipelines. In: Proceedings of the 20th ACM Conference on Information and Knowledge Management (CIKM'11), ACM, Glasgow, Scotland, pages 2237-2240, October 2011.
Download [paper] (462 KB)
Prettenhofer & Stein 2011: Peter Prettenhofer and Benno Stein. Cross-lingual Adaptation using Structural Correspondence Learning. ACM Transactions on Intelligent Systems and Technology, ACM, to appear.
Wachsmuth et. al. 2010: Henning Wachsmuth, Peter Prettenhofer, and Benno Stein. Efficient Statement Identification for Automatic Market Forecasting. In: Proceedings of the 23rd International Conference on Computational Linguistics (COLING'10), ACM, Beijing, China, pages 1128-1136, August 2010.
Download [paper] (128 KB)
Prettenhofer and Stein 2010: Peter Prettenhofer and Benno Stein. Cross-Language Text Classification using Structural Correspondence Learning. In Proceedings of the 48th Annual Meeting of the Association of Computational Linguistics (ACL'10), Association for Computational Linguistics, Uppsala, Sweden, pages 1118-1127, July 2010.
Download: [paper] (540 KB)

Annotierte Textkorpora
Annotierte Textkorpora dienen der Entwicklung und Evaluierung textbasierter Algorithmen, die statistische oder linguistische Verfahren beinhalten. Folgende Korpora werden der Wissenschaft durch das InfexBA-Projekt zur Verfügung gestellt:
InfexBA Revenue Corpus, annotierter Textkorpus
Überarbeitete Version: [Revenue-Corpus-v2.zip] (15,5 MB, enthält alle Dateien)
Annotierte XMI-Dateien: [revenuecorpus_annotated.tar.gz] (6,3 MB)
Unicode Plain-Text: [revenuecorpus_plain.tar.gz] (5,3 MB)
Korpusdokumentation [RevenueCorpus_Documentation.pdf] (24 KB)
Von Domänenexperten annotierter Textkorpus für die Entwicklung und Evaluierung von Information-Extraction-Verfahren im Bereich der Marktinformationen.
LFA-11 Corpus, annotierter Textkorpus
Überarbeitete Version: [LFA-11-Corpus-v2.zip]
(6,7 MB)
Annotierte XMI-Dateien: [lfa-11-corpus.tar.gz] (4,9 MB)
Korpusdokumentation: [lfa-11-documentation.pdf] (64 KB)
Von Domänenexperten annotierter Korpus mit Texten aus zwei Domänen (Music und Smartphones) für die Entwicklung und Evaluierung von Klassifikationsverfahren im Bereich der Genreanalyse (genauer gesagt der Sprachfunktionsanalyse) und der Stimmungsanalyse.
Apache-UIMA-Typsystem, XML-Deskriptordatei
XMI-Typsystem: [infexbaTypeSystem.xml] (12 KB)
Beide Korpora sind bei Bedarf vorformatiert für das Framework Apache UIMA. Die angegebene XMI-Datei spezifiziert das zugehörige Typsystem.

Frei verfügbare Software
RevMarker BA, Firefox Add-on, Version 1.02, 5. Oktober 2010
Download Add-on: [revmarker.xpi] (54 KB)
Kurzanleitung: [RevMarkerBA_GettingStarted.pdf] (519 KB)
Dieses Add-on integriert die InfexBA-Marktanalyse in den Browser Mozilla Firefox. Wahlweise automatisch oder per Knopfdruck wird die aktuell geöffnete Webseite im unten angegebenen Webservice analysiert, um Aussagen über die Umsätze von Firmen und Märkten im Browser zu highlighten. Seit Version 1.02 gibt es zusätzlich die Möglichkeit, die Korrektheit der Analysergebnisse zu bewerten.
msx, Webservice, Version 1.0, 20. August 2010
Webservice: http://jaslab.cs.upb.de:8080/msx/json?content={...}
Dokumentation: [Deutsch] (80 KB, pdf) / [Englisch] (76 KB, pdf)
Der Webservice der Marktanalyse ist ebenfalls frei ansteuerbar. Zu beachten ist, dass Content Extraction auf Client-Seite geschehen muss.
Sentiment Analysis, Web-Anwendung
Online-Tool zur Klassifikation der Stimmung (positiv vs. negativ) eines frei eingebbaren deutsch- oder englischsprachigen Textes. Diese Webanwendung befindet sich auf der InfexBA-Projekt-Webseite der Bauhaus-Universität Weimar.
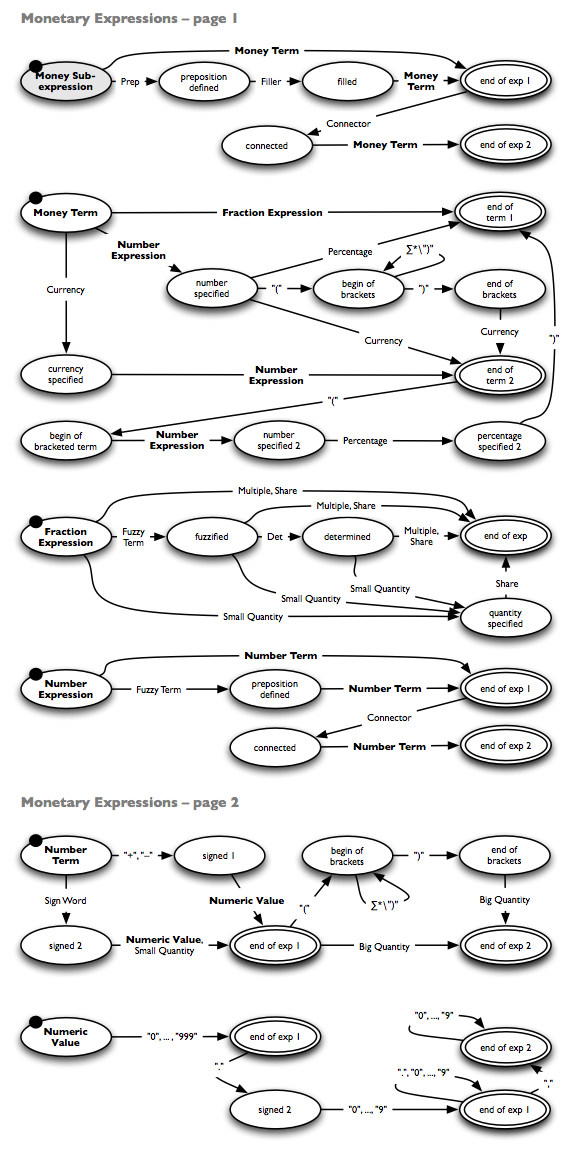
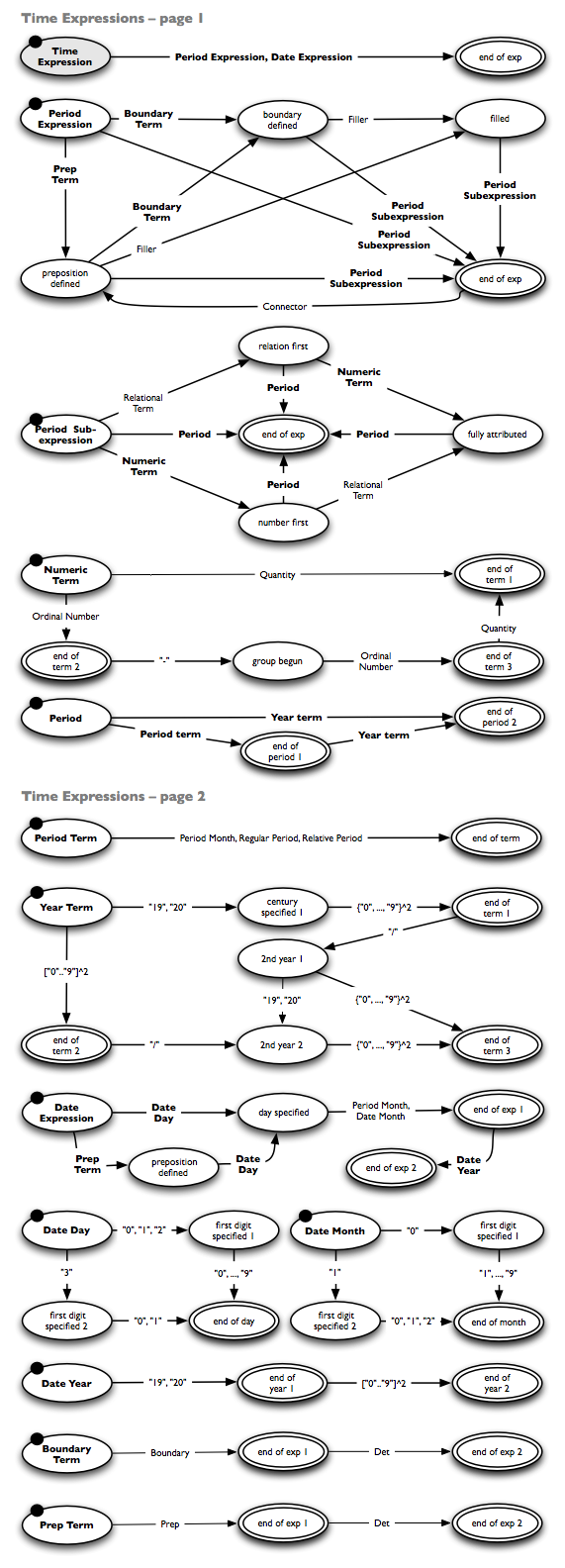
Zeit- und Geldextraktion, Konzept: Reguläre Ausdrücke
{kind=link}
{kind=link}
Innerhalb der InfexBA-Marktanalyse kommen verschiedene Extraktionsverfahren zum Einsatz, wie im oben aufgeführten Paper genauer beschrieben. Die Geld- und Zeiterkennung basieren auf den in Bildern dargestellten endlichen Automaten, die jeweils reguläre Ausdrücke modellieren.
Sprachfunktionsanalyse, Evaluierung für das IJCNLP-Paper
Java-Quellcode und Konfigurationsdateien: [lfa-source.tar.gz] (248 KB)
Weka ARFF-Feature-Dateien [lfa-arff.tar.gz] (4,7 MB)
Folgende Bibliotheken sind notwendig, um den Quellcode zu kompilieren und zu starten: Apache UIMA (Version 2.3), Weka (Version 3.6, möglicherweise auch ältere Versionen), LibSVM (Version 2.x oder neuer), TreeTagger (inklusive Modell für die deutsche Sprache).